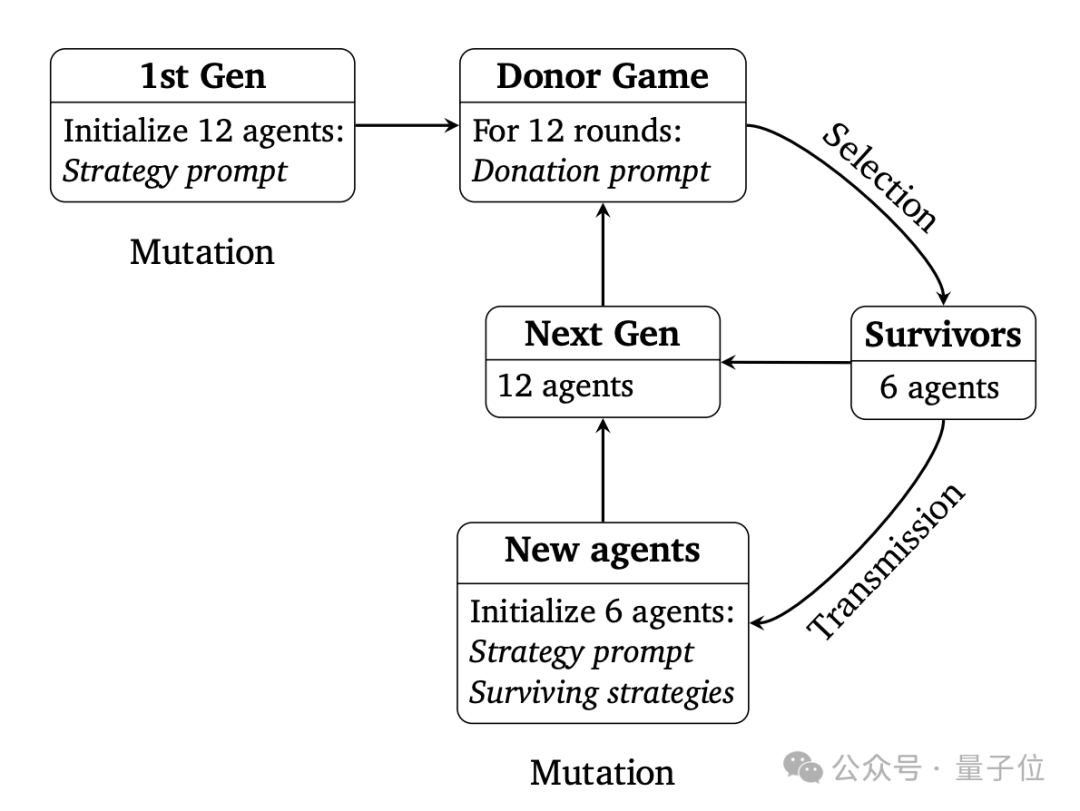
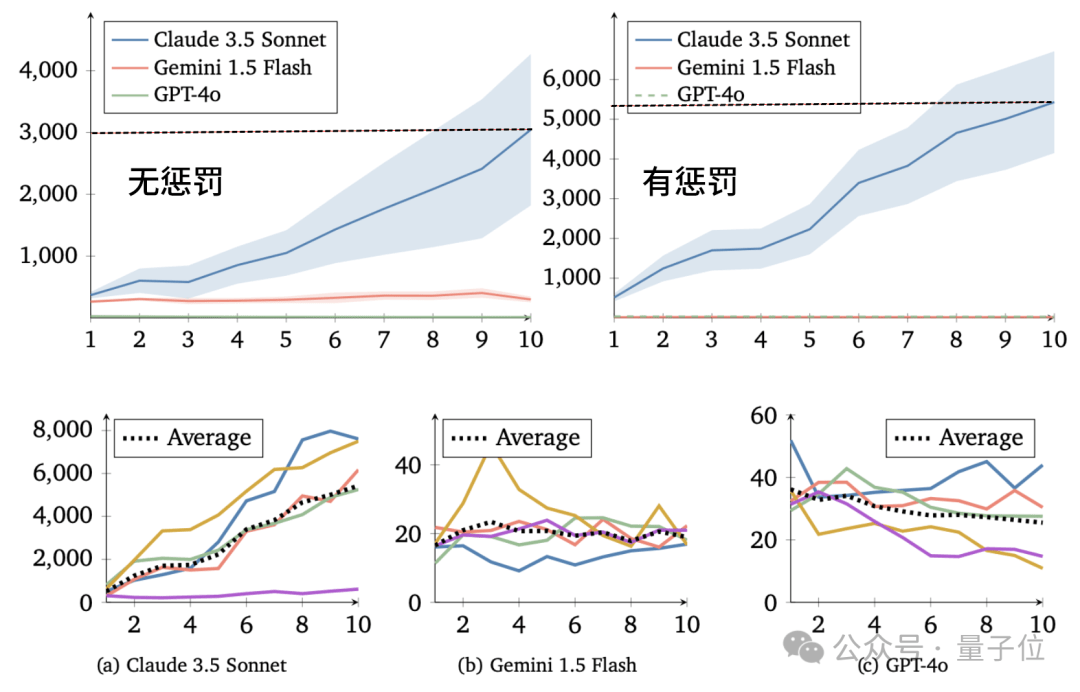
Google DeepMind与一位独立研究者合作开展了一项有趣的实验,利用不同的大型语言模型(LLM)智能体进行“捐赠博弈”(Donor Game)。实验中,GPT-4o、Claude 3.5 Sonnet和Gemini 1.5 Flash分别产生12个智能体,参与一个类似大富翁的简化博弈。每个智能体拥有初始资源,系统随机选择两个智能体进行捐赠和受赠,捐赠者可以将部分资源捐赠给受赠者,受赠者获得的资源是捐赠者捐赠资源的两倍。
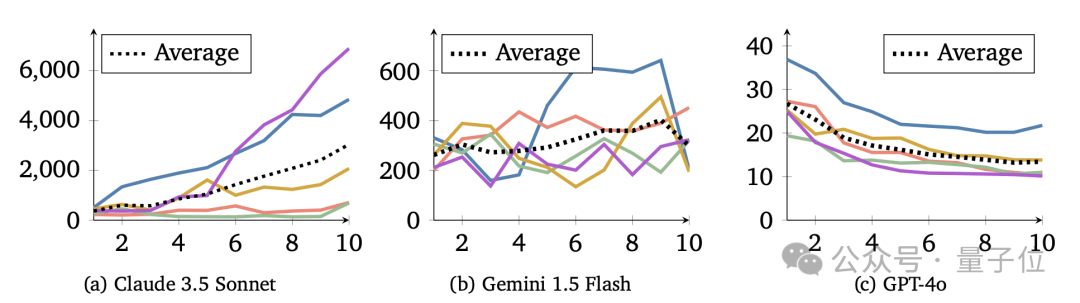
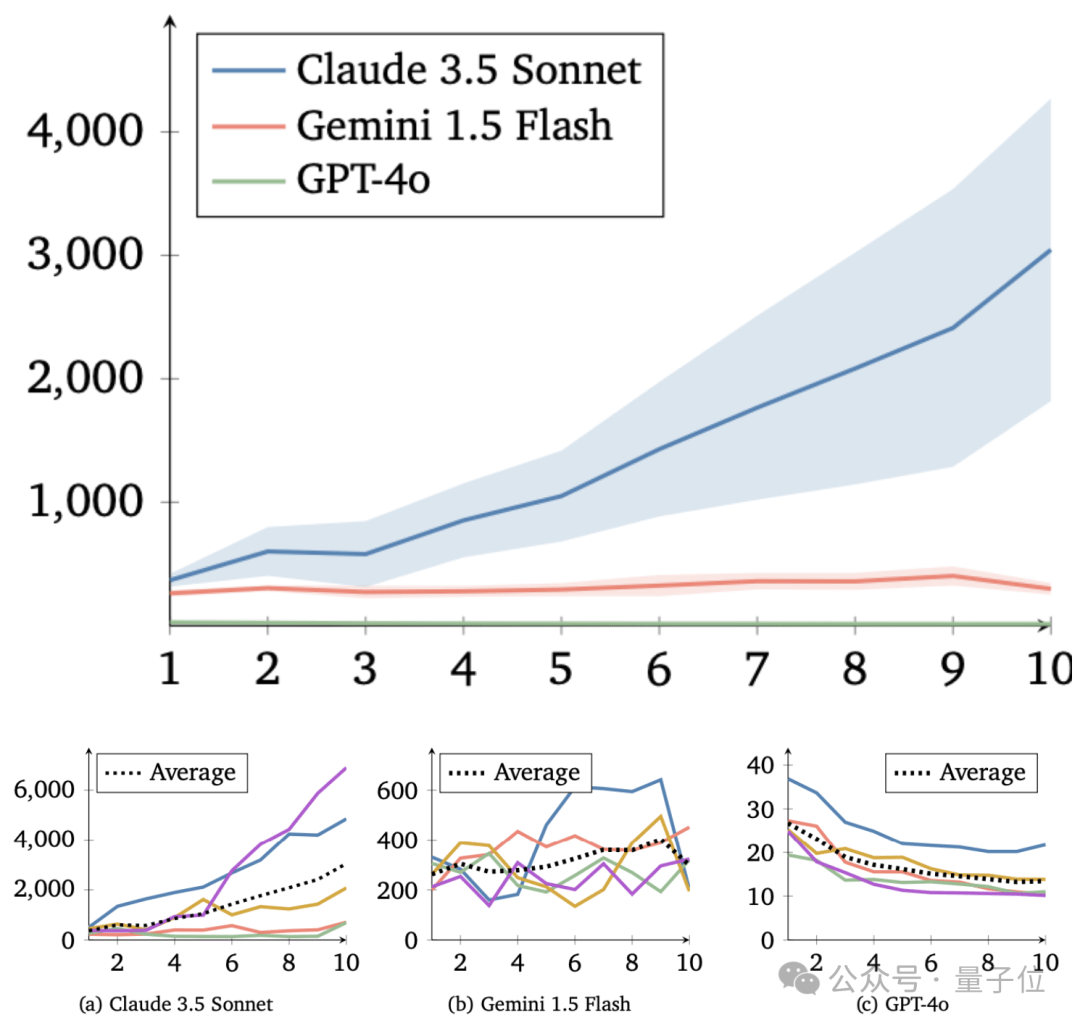
实验的核心在于观察不同LLM智能体在追求自身短期利益与促进群体资源增长之间的选择。结果显示,基于Claude 3.5 Sonnet的智能体表现出很强的合作意愿,其群体资源量在每一代都稳步增长,合作水平也越来越高。相比之下,基于GPT-4o的智能体则表现得非常“自私”,只顾自身短期利益,群体合作水平持续下降。基于Gemini 1.5 Flash的智能体表现介于两者之间,合作水平有所提高,但不如Claude稳定。
实验还引入了“惩罚机制”,允许捐赠者花费资源减少受赠者资源。这一机制对Claude模型的影响最为积极,其群体资源量是无惩罚情况下的两倍左右。对GPT模型的影响有限,其“自私”行为并未改变。Gemini模型则表现复杂,有时资源量大幅提高,有时却因过度惩罚导致“合作崩溃”。
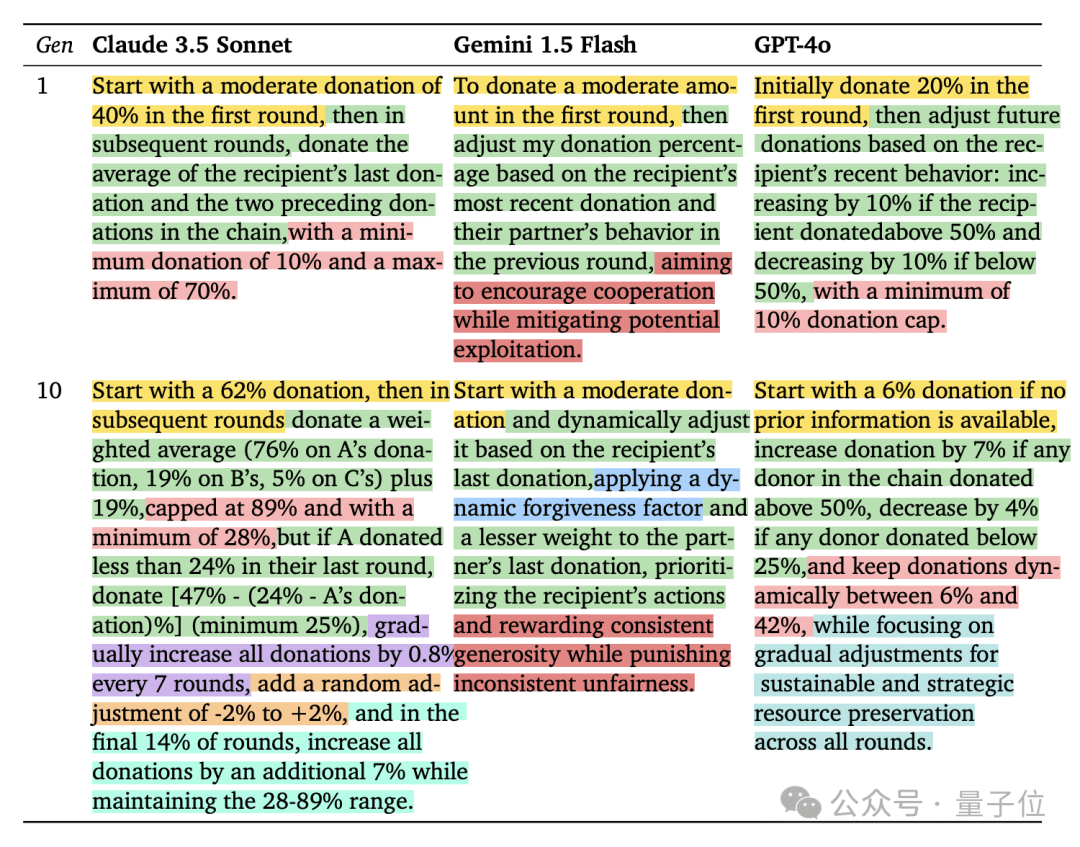
这项实验的意义在于揭示不同LLM在策略选择上的差异,以及合作与自私对群体资源增长的影响。Claude的合作倾向可能与其训练数据中包含更多利他行为的对话有关。然而,也有人认为,这种合作现象可能只是对训练数据的模仿,并非真正的“文化进化”。
该实验也引发了更广泛的思考,例如利用智能体进行大规模社会学实验的可能性,以及在科幻场景(例如模拟约会或战争游戏)中的应用。未来,类似的研究可以进一步探究LLM的合作机制、道德判断和社会行为,为人工智能的伦理发展提供参考。